A new algorithm for finding a visual center of a polygon
We came up with a neat little algorithm that may be useful for placing labels and tooltips on polygons, accompanied by a JavaScript library. It’s now going to be used in Mapbox GL and Mapbox Studio. Let’s see how it works.
The problem
The best place to put a text label or a tooltip on a polygon is usually located somewhere in its “visual center,” a point inside a polygon with as much space as possible around it.
The first thing that comes to mind for calculating such a center is the polygon centroid. You can calculate polygon centroids with a simple and fast formula, but if the shape is concave or has a hole, the point can fall outside of the shape.

How do we define the point we need? A more reliable definition is the pole of inaccessibility or largest inscribed circle: the point within a polygon that is farthest from an edge.
Unfortunately, calculating the pole of inaccessibility is both complex and slow. The published solutions to the problem require either Constrained Delaunay Triangulation or computing a straight skeleton as preprocessing steps — both of which are slow and error-prone.
For our use case, we don’t need an exact solution — we’re willing to trade some precision to get more speed. When we’re placing a label on a map, it’s more important for it to be computed in milliseconds than to be mathematically perfect. So we’ve created a new heuristic algorithm for this problem.
The existing solution
The only approximation algorithm for this task found available online is described by this 2007 paper by Garcia-Castellanos & Lombardo. The algorithm goes like this:
- Probe the polygon with points placed on an arbitrarily sized grid (24x24 in the paper, or 576 points) distributed within its bounding box, discarding all points that lie outside the polygon.
- Calculate the distance from each point to the polygon and pick the point with the longest distance.
- Repeat the steps above but with a smaller grid centered on this point (smaller by an arbitrary factor of 1.414).
- The algorithm runs many times until the search area is small enough for the precision we want.

There are two issues with this algorithm:
- It isn’t guaranteed to find a good solution and depends on chance and relatively well-shaped polygons.
- It is slow on bigger polygons because of so many point checks. For every blue dot in the image above, you have to loop through all polygon points.
However, taking this idea as an inspiration, we managed to design a new algorithm that fixes both flaws.
The new solution
We needed to design an algorithm that would not rely on arbitrary constants, and would do an exhaustive search of the whole polygon with reliably increasing precision. And one familiar concept struck as immediately relevant to the task — quadtrees.
The main concept of a quadtree is to recursively subdivide a two-dimensional space into four quadrants. This is used in many applications — not only spatial indexing, but also image compression, and even physical simulation, where adaptive precision which increases in particular areas of interest is beneficial.
Here’s how we can apply quadtree partitioning to the problem of finding a pole of inaccessibility.
- Start with a few large cells covering the polygon.
- Recursively subdivide them into four smaller cells, probing cell centers as candidates and discarding cells that can’t possibly contain a solution better than the one we already found.
Since the search is exhaustive, we will eventually find a cell that’s guaranteed to be within a global optimum.
How do we know if a cell can be discarded? Let’s consider a sample square cell over a polygon:
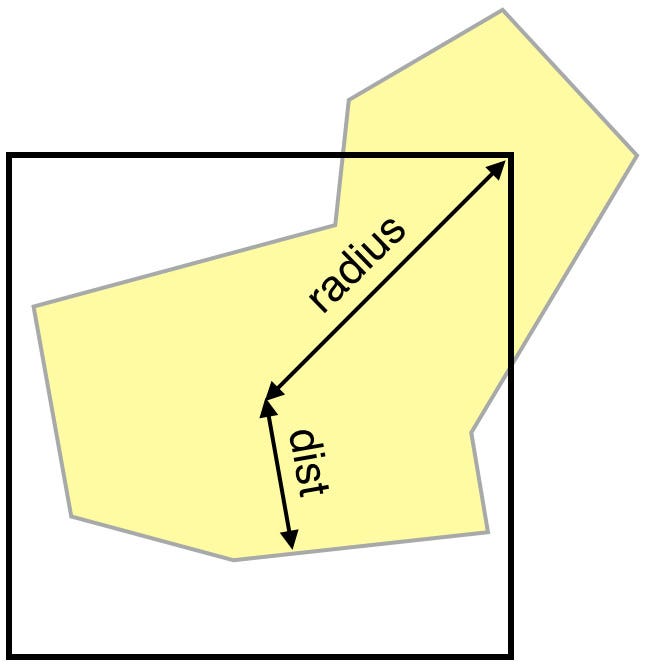
If we know the distance from the cell center to the polygon (dist above), any point inside the cell can’t have a bigger distance to the polygon than dist + radius, where radius is the radius of the cell. If that potential cell maximum is smaller than or equal to the best distance of a cell we already processed (within a given precision), we can safely discard the cell.
For this assumption to work correctly for any cell regardless whether their center is inside the polygon or not, we need to use signed distance to polygon — positive if a point is inside the polygon and negative if it’s outside.
Finding solutions faster
The earlier we find a “good” cell, far away from the edge of the polygon, the more cells we’ll discard during the run, and the faster the search will be. How do we find good cells faster?
We decided to try another idea. Instead of a breadth-first search, iteratively going from bigger cells to smaller ones, we started managing cells in a priority queue, sorted by the cell “potential”: dist + radius. This way, cells are processed in the order of their potential. This roughly doubled the performance of the algorithm.
Another speedup we can get is taking polygon centroid as the first “best guess” so that we can discard all cells that are worse. This improves performance for relatively regular-shaped polygons.
Summary
The result is Polylabel, a fast and precise JavaScript module for finding good points to place a label on a polygon. It is up to 40 times faster than the algorithm we started with, while also guaranteeing the correct result in all cases.
It’s now being ported to C++ and incorporated into both Mapbox GL JS and Native. The module is just 100 lines of code, so check it out!

